CVE-2026-48710: A Maintainer's Perspective
Last week, I published the security advisory GHSA-86qp-5c8j-p5mr on GitHub, and now it seems the project is being aimed at by a barrage of negative press. I want to take a moment to share my perspective on this, and to share my point of view on the vulnerability, and share a bit about the process itself.
What is the vulnerability?
Routing uses the raw HTTP path, but request.url is reconstructed by concatenating http://{host}{path},
where host comes from the Host header. Since the client controls that header, request.url.path can be made
to differ from the path the request was actually routed on.
This matters when a middleware uses request.url.path to guard a route:
from starlette.applications import Starlette
from starlette.middleware import Middleware
from starlette.middleware.base import BaseHTTPMiddleware
from starlette.responses import PlainTextResponse
from starlette.routing import Route
class AuthMiddleware(BaseHTTPMiddleware):
async def dispatch(self, request, call_next):
if request.url.path.startswith("/admin"):
return PlainTextResponse("Forbidden", status_code=403)
return await call_next(request)
async def potato(request):
return PlainTextResponse("Secret potato")
app = Starlette(
routes=[Route("/admin/potato", potato)],
middleware=[Middleware(AuthMiddleware)],
)
Now send a request to /admin/potato with Host: example.com/?. The router still dispatches to the potato
endpoint, because routing uses the raw path. But request.url is reconstructed as http://example.com/?/admin/potato,
so request.url.path is /. The middleware's check never fires, and the secret leaks.
You may look at this and say: "uau, that's a pretty bad bug". It can be. But the assumptions matter when you reason about where the vulnerability actually lives:
- An application uses path-based authorization in middleware. This is an application pattern built on top of Starlette, not something Starlette does for you.
- Routing itself is never fooled. The router dispatches on the raw HTTP path, so the endpoint that runs is always the correct one. The divergence only bites code that re-derives authorization from the reconstructed URL.
- There's no CDN, load balancer, API gateway, or fronting web server validating the
Hostheader. Any of those neutralizes the attack by rejecting malformed values.
There's a more fundamental point here, and Giovanni Barillari put it well in the advisory
thread: authorization and authentication should not be based on the request's path, host, or query string in the first
place. That's a fragile pattern regardless of this bug. Trailing slashes, case sensitivity, percent-encoding, and path
normalization all bite the same code in the same way. The Host header is just one more thing that can make the
string you matched on differ from the request you actually served.
In short, the vulnerability came from the application pattern and the deployment, never from something Starlette intended.
Why was there even a CVE then?
I think the article OSTIF did explains this well:
This bug is a classic “responsibility gap” where if this maintainer didn’t patch, thousands of exposed projects would have to individually secure their projects. In doing this work, they’ve voluntarily taken on the responsibility to protect the ecosystem from long-term systemic harm. As with all open source projects, they owed us nothing and could have left this to be everyone else’s problem and took the extraordinary steps of helping the ecosystem. Please consider donating to Kludex: https://github.com/sponsors/Kludex
I think this summarizes it well.
On the disclosure process
I want to be fair: the people at X41 D-Sec were mostly polite, apologized when I pushed back, and were clearly acting in good faith. But there are a few things about the process I disagree with.
The first was the initial deadline. The very first message imposed a roughly one-month disclosure window and offered a joint call "in 2 or 5 days". That treats unpaid maintainers like a corporation with an on-call security team. Everyone involved in the internal discussion has a full-time job and maintains these projects in their free time. To their credit, X41 walked the deadline back once this was raised.
The part I find hardest to accept is, near the end, they suggested publishing the advisory before a patch was available. That is horrible practice. A public advisory with no available fix leaves every affected user exposed with nothing to do but wait, while attackers get the exact same information. The whole point of coordinated disclosure is that the fix lands first. Suggesting the reverse, on a package this widely deployed, is the opposite of protecting users.
The other thing that bothered me is that X41 built badhost.org, a branded landing page with a logo, a name, and an Internet-wide scanner. That is marketing a vulnerability. Spinning up a dedicated site the moment the advisory drops gives users no time to react: the CVE databases haven't propagated yet, tools like Dependabot haven't fired their alerts, and most people haven't even had the chance to bump the dependency. The branding gets the attention; the people running the affected software get to find out from a headline.
Unprofessional behavior from Ars Technica
The article Ars Technica published mentioned this:
The developer of Starlette didn’t immediately reply to an email seeking confirmation of the assessment and additional information.
For public disclosure, this is the email they sent to me:
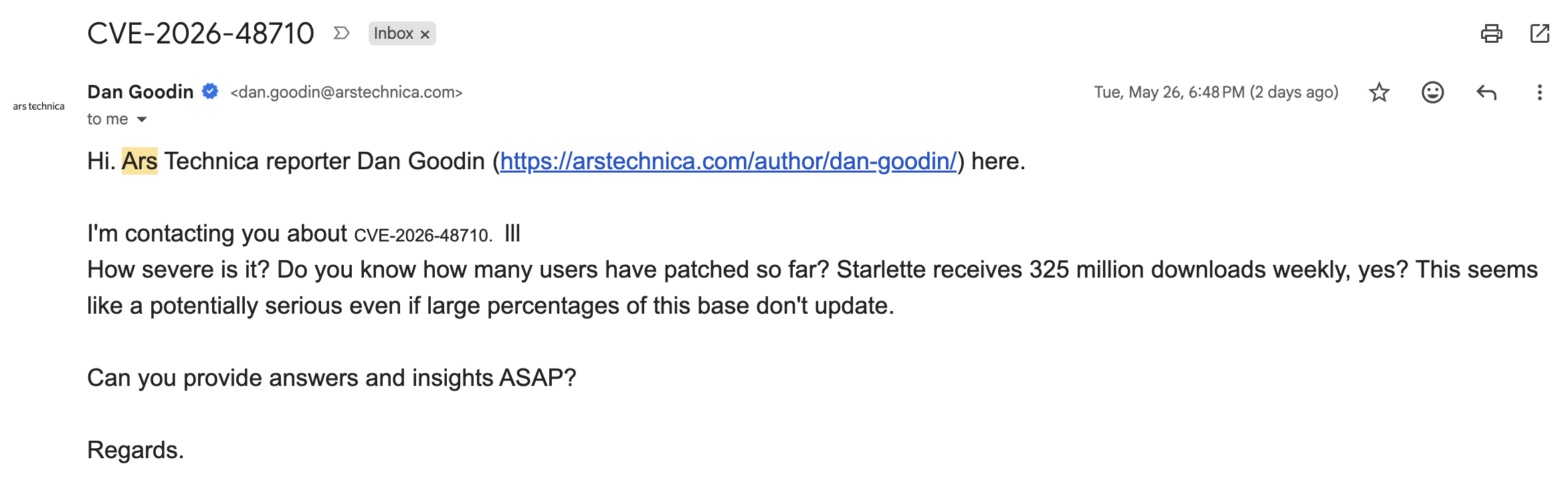
This email was sent couple of hours before the article was published. I feel like it's in my right to not reply to the rude, and demanding tone of this email. I've never interacted with this person before, and I don't think I owe anything to them.
I don't read Hacker News or Reddit, unless some friend points me to a specific thread. Also... I got shamed by my friends because I didn't know what Ars Technica was. But after today, I'm pretty sure I'll not be reading anything from them anyway.
The burden of triaging security advisories
Least but not last, I want to talk about the burden of triaging security advisories. I don't have a security team, and every advisory lands on me personally. Most weeks I'm reviewing one almost every day, and the majority are noise - coding agents generating plausible-looking reports that take real time to disprove. A genuine one like this is rare, and it still has to compete for the same evenings and weekends as everything else.
I wrote about this in the Starlette 1.0 post: advisories are the tricky part of maintenance, because dismissing a real one is dangerous and entertaining a fake one is expensive. I'll keep doing it, but it's worth understanding the cost behind the calm response you eventually see.
What you should do
Upgrade to Starlette 1.0.1 or later, which validates the Host header
and rejects malformed values.
Beyond that: don't base authorization on request.url.path. If you need the routed path, use
request.scope["path"], which is never reconstructed from the Host header. Better yet, don't make authorization
decisions on path strings at all.
Thank you
The thing that stuck with me most was not the criticism, but how many people pushed back on the framing without being asked to. On the Ars thread, person after person took the time to explain that this was an old-fashioned bug, not "AI slop", and that the article's spin did readers a disservice. The comments attacking the project were few, and mostly down voted.
To everyone who read past the headline and engaged with what actually happened: thank you. 


